Corrective Augmentation for Robotics via Novel-View Synthesis
Abstract. Expert demonstrations are a rich source of supervision for training visual robotic manipulation policies, but imitation learning methods often require either a large number of demonstrations or expensive online expert supervision to learn reactive closed-loop behaviors. In this work, we introduce SPARTN (Synthetic Perturbations for Augmenting Robot Trajectories via NeRF): a fully-offline data augmentation scheme for improving robot policies that use eye-in-hand cameras. Our approach leverages neural radiance fields (NeRFs) to synthetically inject corrective noise into visual demonstrations: using NeRFs to generate perturbed viewpoints while simultaneously calculating the corrective actions. This requires no additional expert supervision or environment interaction, and distills the geometric information in NeRFs into a real-time reactive RGB-only policy. In a simulated 6-DoF visual grasping benchmark, SPARTN improves offline success rates by 2.8× over imitation learning without the corrective augmentations and even outperforms some methods that use online supervision. It additionally closes the gap between RGB-only and RGB-D success rates, eliminating the previous need for depth sensors. In real-world 6-DoF robotic grasping experiments from limited human demonstrations, our method improves absolute success rates by 22.5% on average, including objects that are traditionally challenging for depth-based methods.
Reactive closed-loop grasping of moving targets
The video below shows real-world rollouts of SPARTN policies given moving target objects. Our reactive closed-loop policies are able to adjust their trajectories mid-execution to successfully navigate towards and grasp their targets. All clips are sped up by 4x.
Method overview
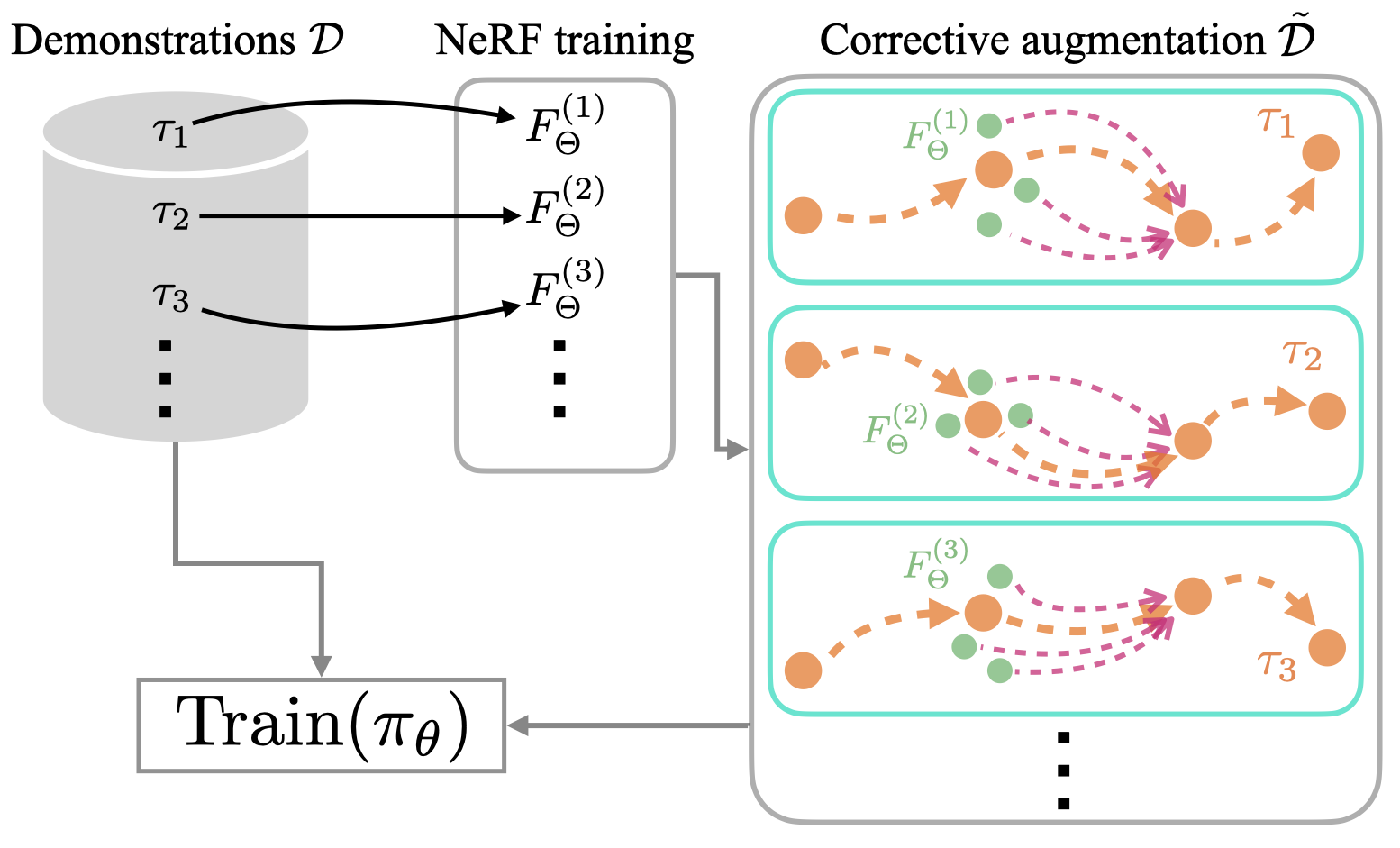
SPARTN is a NeRF-based data augmentation for behavior cloning better eye-in-hand visual grasping policies. Left: To address the compounding errors issue in behavior cloning, SPARTN simulates recovery in each demonstration by NeRF-rendering high-fidelity observations from noisy states, then generates corrective action labels. This augmentation process is fully offline and requires no additional effort from expert demonstrators nor online environment interactions. Right: An overview of the SPARTN training process. A NeRF is trained for each of the original demonstrations in \(\mathcal{D}\). We use these NeRFs to generate visual corrective augmentations for each demonstration and collect them in \(\tilde{\mathcal{D}}\). The policy \(\pi_\theta\) can be trained on \(\mathcal{D}\) and \(\tilde{\mathcal{D}}\) using standard behavior cloning methods.

Real-world policy rollouts: SPARTN success cases
Here we show sample evaluation trials where the SPARTN policies succeed while the behavior cloning (BC) policies fail, given the same initial object and end-effector configurations. The target objects include the following: banana, thin box, steel water bottle, wine glass, Lubriderm bottle, white tape roll, tupperware, and fork.
Overall, we see that the SPARTN policies navigate toward the target objects better, avoid collisions with higher probability, executes actions with higher precision, and reattempts the grasp more successfully after an initial miss. All videos are sped up by 4x.
Real-world policy rollouts: SPARTN failure cases
Below we show sample evaluation trials where both SPARTN and BC policies fail, given the same initial object and end-effector configurations. Even in these failure cases, SPARTN qualitatively performs better, nearly grasping the object in some cases, and dropping the object soon after grasping in other cases. All videos are sped up by 4x.
In some cases, the SPARTN policies fail to grasp the target object while the BC policies succeed, given the same initial object and end-effector configurations. While we record such cases as failures for the SPARTN policies, the qualitative results in the videos below reveal that SPARTN often comes close to success in these scenarios. All videos are sped up by 4x.
Simulated policy rollouts
Here we show representative rollouts of the best performing SPARTN and BC policies attempting to grasp each of the nine heldout evaluation objects: bleach bottle, bowl, brick, cracker box, mug, mustard bottle, soup can, spam can, and sugar box. Recall that to calculate success rates, we evaluate each heldout object for 10 episodes while varying the initial object and robot poses. The SPARTN policy shown here achieved an 89% success rate across all objects and evaluations, while the BC policy achieved a 30% success rate.
Overall, we see that the SPARTN policy more precisely controls the gripper to a successful grasping pose, while the BC policy is more likely to miss the object entirely or make imprecise motions that lead to failed grasps or knocking the object over.
Example NeRF renderings from augmented poses
To create our augmentations, we sample perturbations to the camera poses in the original demonstrations and render the corresponding augmented observations using NeRF. Here we show the NeRF-rendered observations corresponding to the sampled perturbations of a simulation (left) and real-world (right) demonstration.
Simulation
Real-world